
アラビア語関連書籍のPDF化と文字認識(OCR)については『アラビア語学習書の電子書籍化(自炊・PDF化)』で紹介した通りです。このページでは自宅で行う紙の書籍のデジタル化とアラビア語・日本語・英語を含む複数言語のOCR作業についてまとめてみたいと思います。
ScanSnapとアラビア語OCR
富士通 ScanSnap
https://scansnap.fujitsu.com/jp/
ScanSnapは富士通の製品で、自宅で書籍を電子化したい人たちに買い支えられてきた定番商品です。
OCR関連の設定
ABBYY FineReader for ScanSnap
https://www.pfu.fujitsu.com/imaging/downloads/manual/ss_webhelp/jp/help/webhelp/topic/ope_appli_abbyy_detail.html
ScanSnapの文字認識には海外でも多言語対応しているOCRソフトとして有名なABBYY FineReaderが使用されています。アラビア語についてはOCRパックを追加することで読み取りができるようになります。
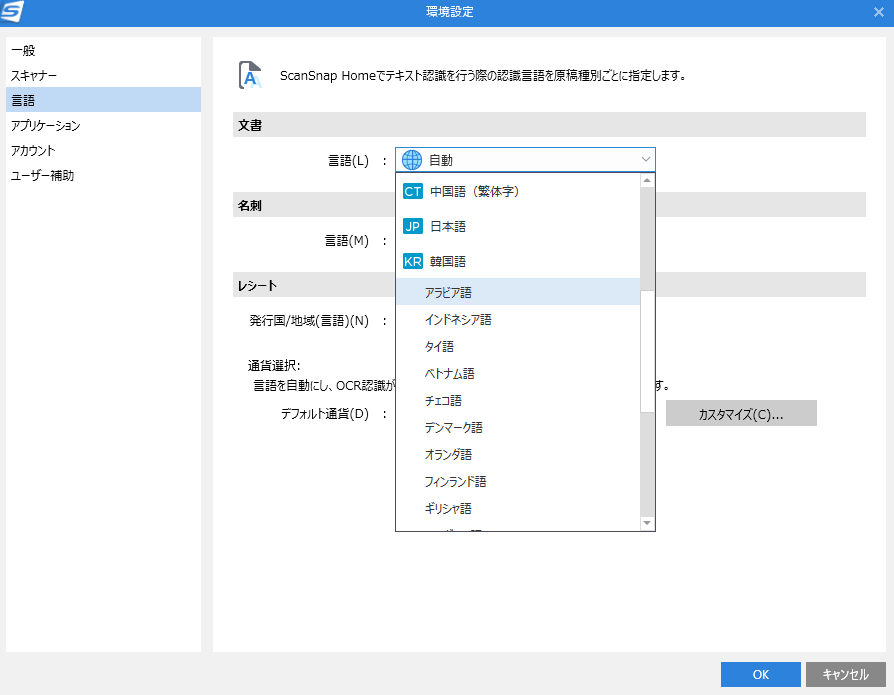
ScanSnapの管理画面にある環境設定メニューから読み取り時の言語を選択できますが、本家のABBYY FineReader PDF 15と違って自動もしくはアラビア語といった感じでどれか1つしか選べないようでした。(本家はチェックを入れて日本語+英語+アラビア語のようなセットで指定ができます。)
実際のスキャン作業

カッターや裁断機で製本されている書籍の背表紙部分をカットします。

サクッと背表紙が外れました。

ScanSnapに投入。上限のページ数が決まっているので、数回に分けてスキャンし1つのPDFファイルとして保存します。
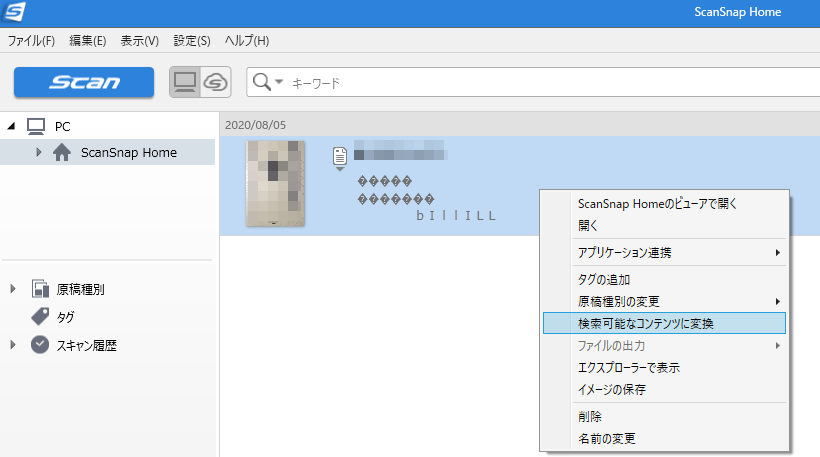
スキャン後、右クリックで「検索可能なコンテンツに変換」を選ぶと設定した言語での文字認識作業が開始します。
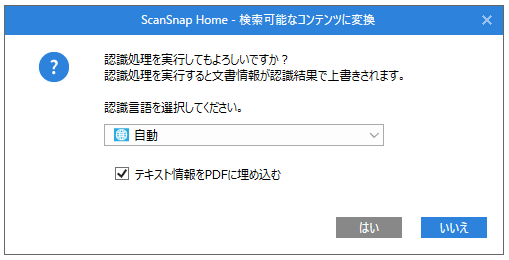
確認画面でもう一度認識言語をどうするかを聞かれます。
ABBYY FineReader PDF 15のように、文字認識作業の結果を確認したり手入力で修正したりするOCRエディタは付属していません。ScanSnapで電子化し、後はお任せでOCR情報をPDFに埋め込んでおしまいといった感じです。
ABBYY FineReader PDF 15
ABBYY FineReader PDF 15
https://www.abbyy.com/ja/finereader/
ScanSnapのおまけとしてついてくるABBYY FineReader for ScanSnapとは違う、非常に多機能な本家のソフトウェアです。価格も高めです。
購入方法
ソフトウェアはメーカーサイトからクレジットカード払い等で購入・ダウンロードできます。値引き無しで買うと高くつくので、まずはアメリカに多数あるクーポンサイトで割引コードを入手することをおすすめします。
有効な割引コードを探してコピーします。
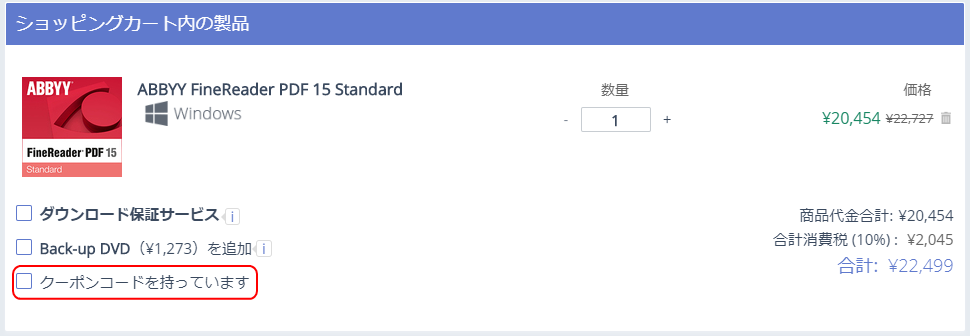
クーポンコードを入力すると割引が適用され値引きが行われました。
ちなみに「ダウンロード保証サービス」という再ダウンロード可能なオプションを別途購入しないと1回ダウンロードしたきりになるようです。ダウンロードしたら外付けメモリ等に保存しておいた方が良いかもしれません。
PDFファイルのアラビア語認識作業
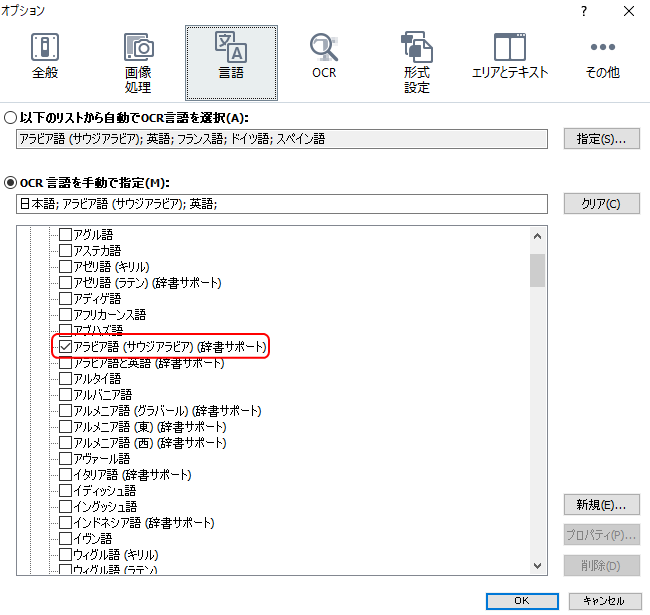
ScanSnap版よりもOCR言語の細かい手動設定ができます。指定したい言語にチェックを入れて複数を同時に設定しておくことができます。
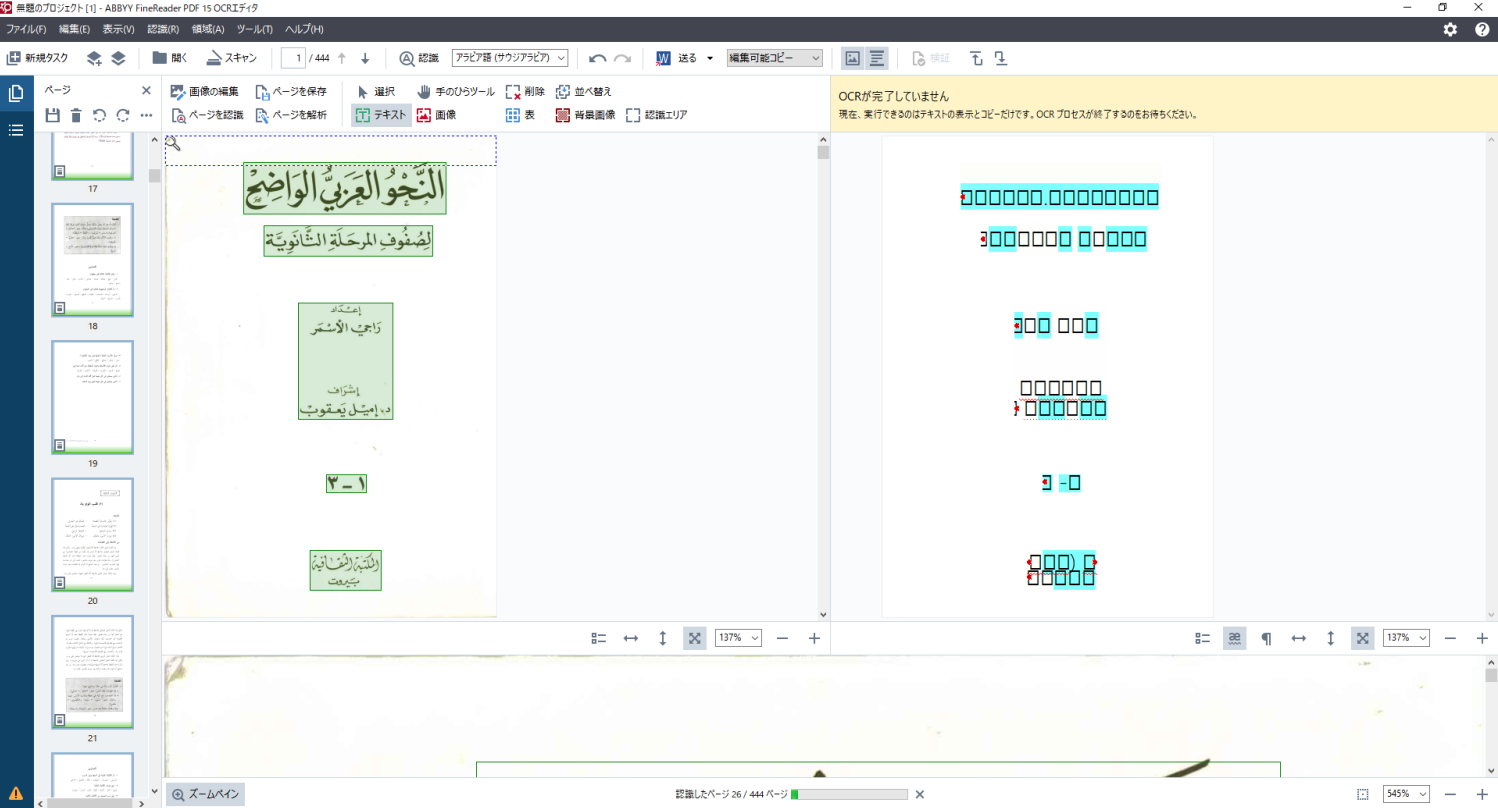
OCR作業はOCRエディタという画面で行います。「認識」ボタンを押すと文字認識作業が始まります。
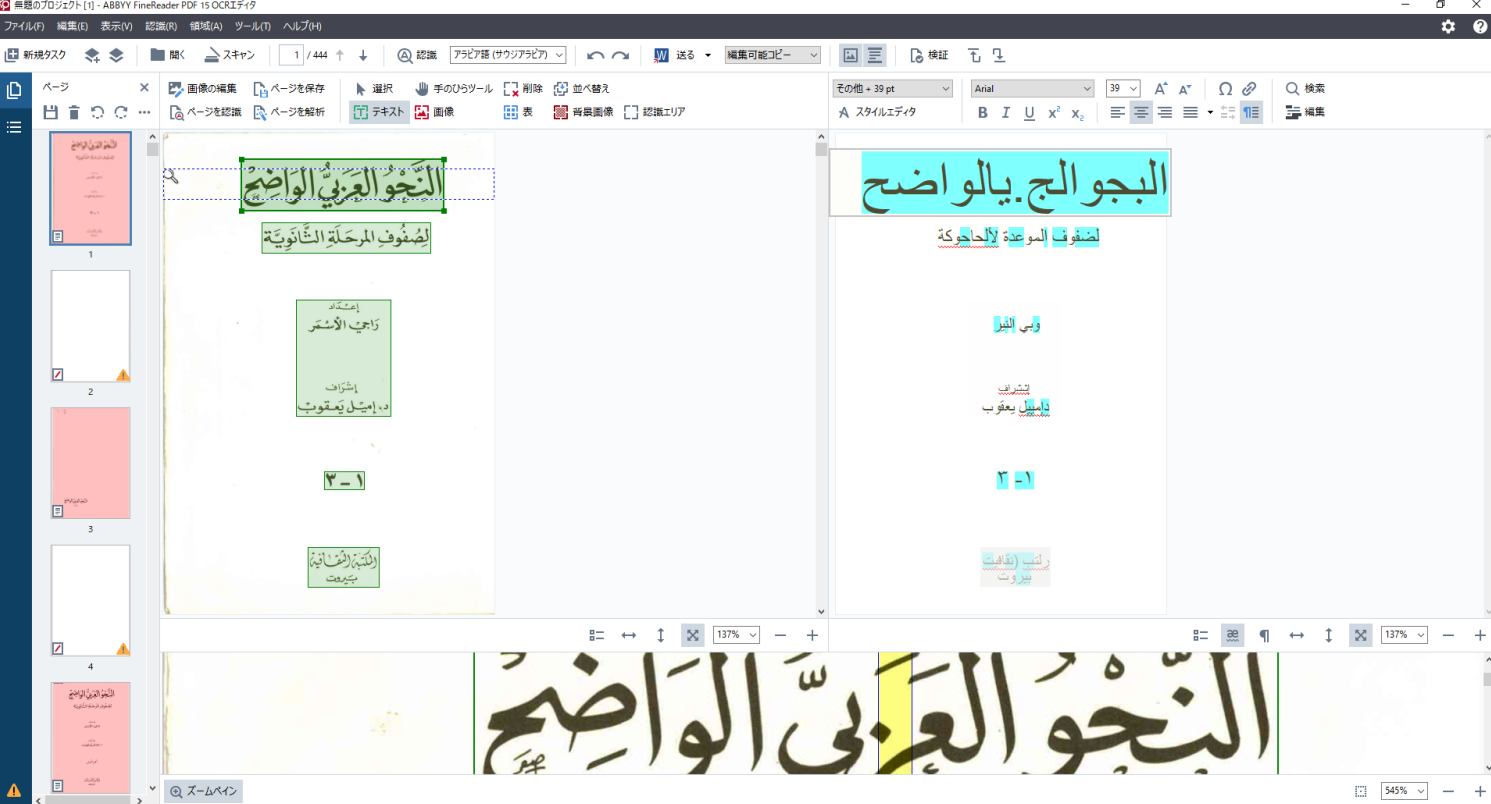
OCR作業が完了し、右側に読み取り結果が表示されました。母音記号がついている部分や手書き系の書体はとても苦手で正常認識率がとても低いです。
埋め込みテキストの修正

OCRエディタなので、自力での入力により正しい埋め込みテキストに修正することができます。
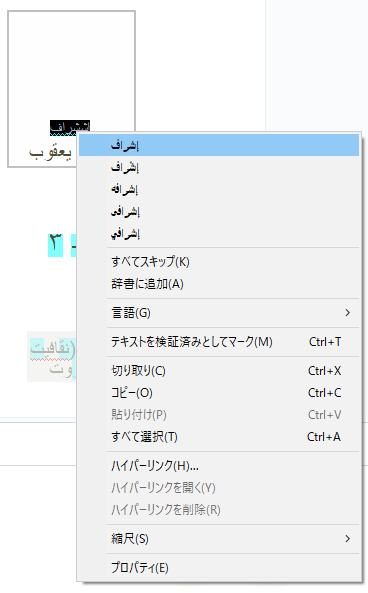
辞書つきなので右クリックにより修正候補を見ることができます。
ABBYY FineReaderの苦手なアラビア語文書

ABBYY FineReaderは日本語とアラビア語が入り組んだ文書、母音記号がついている部分の文字認識がとても苦手です。そのため母音記号がたくさん書かれた文法書のOCR作業での活躍は期待できません。
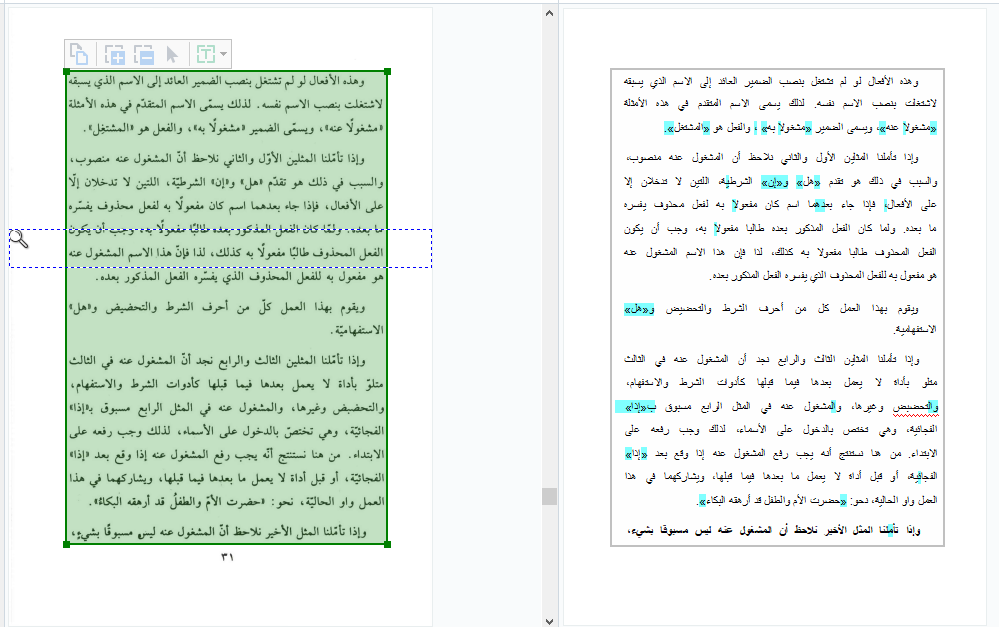
母音記号が無い書籍の認識率はかなり良いです。このぐらいであれば文書内検索のためにOCR情報をPDFファイルに埋め込むだけの価値はあると思いました。
